人工智能实验记录_2022spring
课程学习参考资料:
LAB1 Dijkstra
要求
用python实现dijkstra最短路径算法,并完成以下两个任务。
任务一
给定无向图,及图上两个节点,求其最短路径及长度
要求:使用Python实现,至少实现Dijkstra算法输入
第1行:节点数m 边数n;
第2行到第n+1行是边的信息,每行是:节点1名称 节点2名称 边权;
第n+2行开始可接受循环输入,每行是:起始节点名称 目标节点名称。
输出最短路径及其长度。
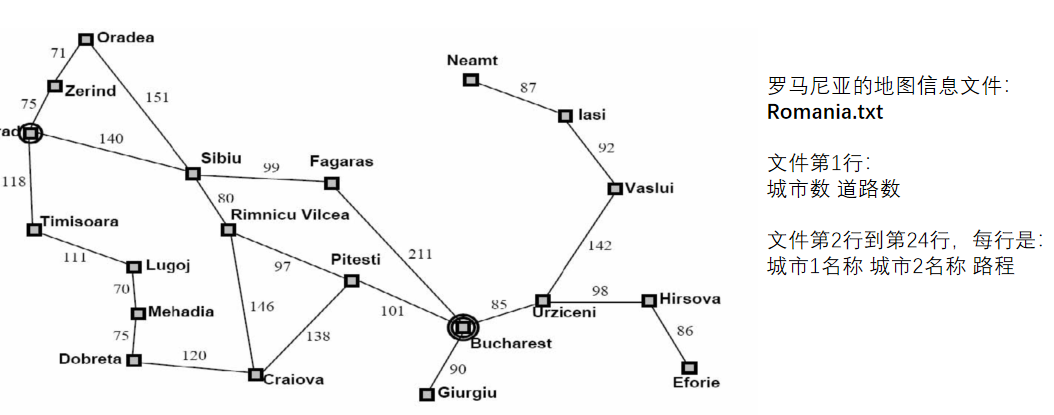
任务二:罗马尼亚旅行问题
你是一名正在罗马尼亚旅行的游客,现在你急需从城市1赶到城市2搭乘航班,因此,你需要找到从城市1到城市2的最短路径。
请基于以上最短路径程序,扩展实现一个搜索罗马尼亚城市间最短路径的导航程序,要求:
出发城市和到达城市由用户在查询时输入
对于城市名称,用户可以输入全称,也可以只输入首字母,且均不区分大小写向用户输出最短路径时,要输出途经的城市,以及路径总路程
输出内容在直接反馈给用户的同时,还需追加写入一个文本文件中,作为记录日志

参考资料:
实验内容
原理
首先是需要对节点的信息进行处理,不同于以前的纯数字节点,现在要处理带名字和距离甚至更多信息的节点,所以可以选择使用使用类来封装节点。
对于实验任务中要求的简单的情况,这里可以使用字典进行节点名字与距离的对应,使用邻接表的数据结构存取无向图。
初始化:dist(起点)=0,其他点到起点的距离 dist 均为 inf 状态数组st都为0
这里使用优先队列优化的dijkstra算法,往优先队列q里面存元组:(城市目前的距离,该城市名字) 。
这样子每次就可以从优先队列取出 已确定最短路径集合S 的最短邻边,然后将其移到 已确定最短路集合S 中。对刚被加入的结点的所有出边执行松弛操作(判断加入前后dist有没有更短)。
一直重复直以上步骤到优先队列q为空结束。
注:以上是基于任务二分析,同样适用于更简单情况的任务一
伪代码
对上面算法原理进行以下整合得到以下伪代码:
1 | dijkstra(start,end): |
关键代码
然后对伪代码进行实现,得到以下代码:
1 | def dijkstra(start, end, city_list, graph): |
优化
可以对以上的基础代码进行封装优化:
引入函数和类,提升代码灵活性和复用度。
处理城市的输入,分割整行字符串的输入
处理用户对于查询路径的输入
- 对用户只输入城市首字母(大小写)的可能进行处理
- 若输入的城市不存在 或者 有多种可能性 的可能进行处理
处理具体最短路径的输出,优化可读性
处理文件的读取写出,从文件中读取输入,对可能输出的最短路径进行记录,以便于复用
1 | class Travel: |
实验结果及分析
需要处理的城市节点是:
Arad → Bucharest
Fagaras → Dobreta
Mehadia → Sibiu
然后对优化过的代码直接进行城市首字母的输入,进行最短路径的查询,这里可以得到最短路径的具体途径城市,以及最短路径的长度。

这里输入的城市信息存在文件里面之中进行读入,最后生成结果之后对输出的结果进行写入文件操作,写入text.txt中。

思考题
如果用列表作为字典的键,会发生什么现象?用元组呢?
会出现错误,在python中可以使用字典键值key配对元素,而这个字典键值可以是整数、字符串,、元组,但不可以是列表list,原因是‘整数、字符串,、元组’都是不可变数据类型,而列表是可变数据类型,有可能导致字典键值的改变,这是不被允许的。
我们可以将列表转换为不可变对象来处理,比如转换为元组。
在本课件第2章和第4章提到的数据类型中,哪些是可变数据类型,哪些是不可变数据类型?
可变/不可变数据类型:变量值发生改变时,变量的内存地址不变/改变
不可变数据类型:Number、String、Tuple
可变数据类型:List、Dictionary、Set
验证代码:
1
2
3
4
5
6
7
8
9a = [1, 2, 3]
print(id(a))
a = [1, 2, 3]
print(id(a))
a.append(4)
print(id(a))
a += [2]
print(id(a))
print(a)
LAB2 逻辑归结
要求
编写程序,实现一阶逻辑归结算法,并用于求解给出的三个逻辑推理问题,要求输出按照如下格式:
2
3
4
5
6
7
8
9
2. (R(a),Q(z),¬P(a))
3. R[1a,2c]{X=a} (Q(g(a)),R(a),Q(z))
… …
“R” 表示归结步骤.
“1a” 表示第一个子句(1-th)中的第一个 (a-th)个原子公式,即P(x).
“2c”表示第二个子句(1-th)中的第三个 (c-th)个原子公式,即¬P(a).
“1a”和“2c”是冲突的,所以应用最小合一{X = a}.
实验目的:加深对归结原理进行定理证明过程的理解,掌握基于谓词逻辑的归结过程中子句变换过程、替换与合一算法即归结策略等重要环节,进一步了解实 现机器自动定理证明的步骤。
参考资料:
Python3 正则表达式 | 菜鸟教程 (runoob.com)
re — Regular expression operations — Python 3.11.2 documentation
Resolution Algorithm in Artificial Intelligence - GeeksforGeeks
实验内容
算法原理
本次实验的目的:从已知事实和规则(知识库)中提取有用信息(谓词、常变量、函数式),然后推理一个提问是否成立(可满足的)
要得到以上的结果,我们有定理:
- S |- () 当且仅当 S |= (),而S |= () 当且仅当 S 是不可满足的
- 所以有 KB |= α 当且仅当 KB ∧¬α 不可满足,于是可以通过反证法证明KB |= α
根据以上知:要从知识库 KB 推理 α 是正确,即证明 KB→α 是重言式,使用反证法来证明 KB ∧¬α 是永假式
所以就得到归结算法:
将 α 取否定,加入到 KB 当中
将更新的 KB 转换为 clausal form 得到初始子句集 S
反复调用单步归结
- 如果得到空子句,即 S |- (),说明 KB ∧¬α 不可满足,算法终止,可得KB |= α
- 如果一直归结直到不产生新的子句,在这个过程中没有得到空子句,则 KB |= α 不成立
单步归结
本次实验要求实现一阶逻辑归结算法,并且要求解给出的三个逻辑推理问题,这要求注重于单步归结的实现过程、空子句的生成过程。
单步归结的实现:
使用 最一般合一算法 从两个子句中得到相同的原子,及其对应的原子否定
去掉该原子并将两个子句合为一个,加入到S子句集合中
如果该子句是空子句() 则结束循环
伪代码
1 | 输入更新后的KB(KB & ¬α) |
关键代码/步骤
知识库转换为clausal form
这里引用re库利用正则表达式对原始信息处理,按照逗号划分子句的事实
然后对事实去除括号,分割成谓词、变量和常量的形式
结果以列表的形式存入子句集 s 中
1 | s = [] |
接下来进入循环判断:是否存在原子及其的否定(如On和它的否定¬On)
1 | # 返回谓词的非 |
最一般合一
合一过程:在归结过程中,寻找项之间合适的变量置换使表达式一致的过程
若存在一个代换 s ,使得二个文字 L
1 ~与 L2进行代换后,有 L1与 ~L2为互补文字,则 L1与 L2 ~为可合一的,这个代换 s 称为合一元(unifier)
在进行合一前,首先先要进行合一的判断:
判断表示文字的表的长度必须相等,并且谓词是否相同
(这个在前面的进入循环判断已经实现)
判断它们所对应的表的各个项是否能够匹配:
- 变量可与常量、函数或变量匹配
- 常量与常量,函数与函数,谓词与谓词相等才可以匹配。不同的常量,函数,谓词之间不能匹配
也就是说,在一阶逻辑归结算法中,在判断项的匹配时可以抽象成3种情况:
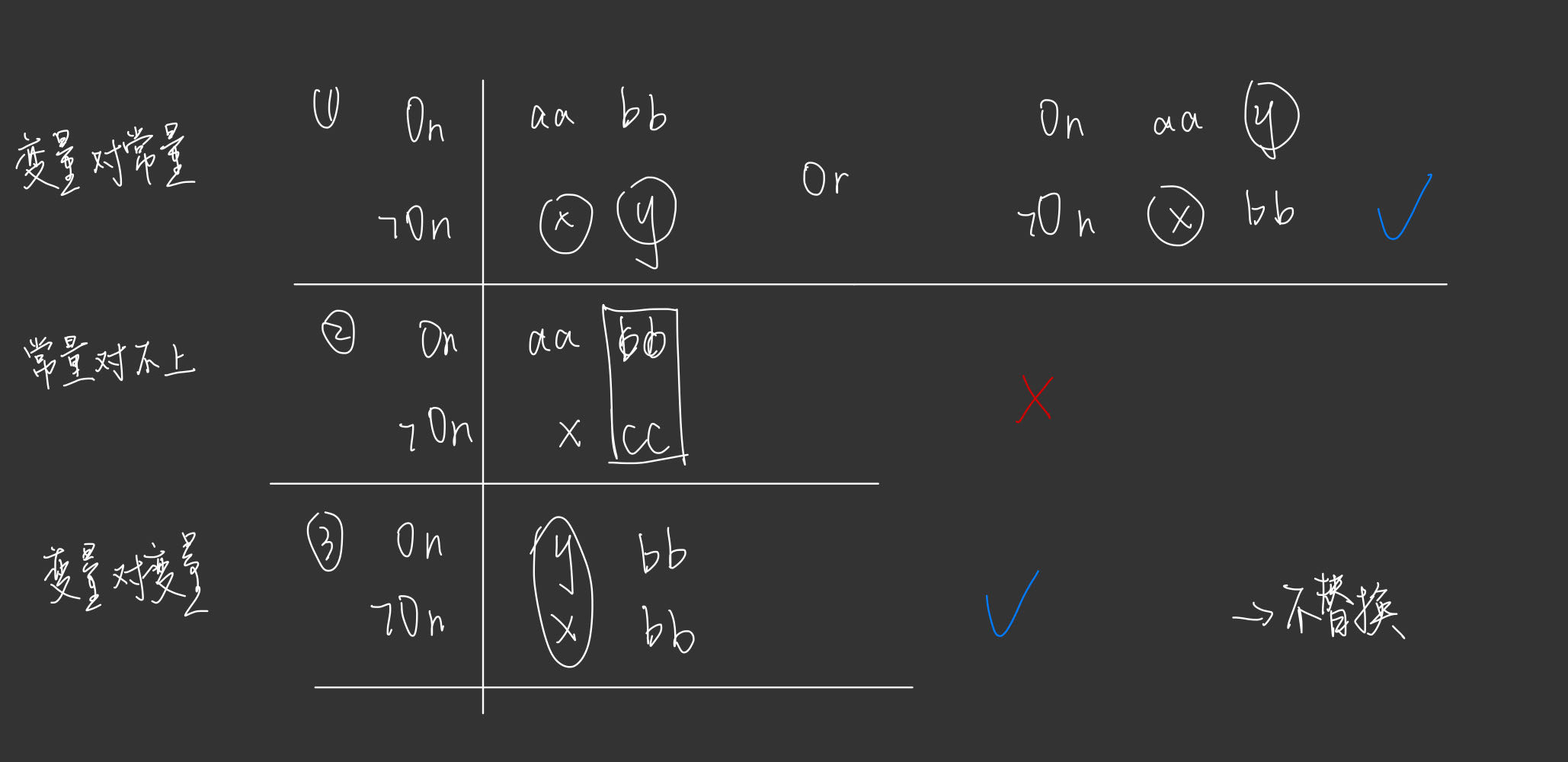
其中只有常量对不上常量的情况不能进行合一。
值得注意的是,变量对变量的情况虽然是可以进行合一的,但是为了缩短子句集s的长度,这里不将它记录到变量替换assignment中,以及退出下面的新子句的生成。
1 | # 判断是否为变量 |
对两个子句进行变量替换
这里首先对变量替换记录进入了assignment(两个子句的变量替换),需要对两个子句中所有记录到的变量进行变量的替换。
使用列表修改多个词语,语法:new_lists =[new_word if i in replace_list else i for i in lists]
1 | # 进行变量替换 |
记录变量替换情况
由于在前面的合一判断中通过,所以此时可以进行变量替换的记录assignment
- 记录assignment:先找到两个子句中的变量,然后往assignment的最后一个元素列表中添加元组 (变量,常量),表示这两个子句的变量替换为该常量。
- 记录parent:往parent的末尾加入元组 (第1个子句的idx,事实的idx,第2个子句的idx,事实的idx)
1 | parents.append((i, ki, j, kj)) |
新子句的生成
先判断能否生成新子句,这里有两种情况可以进行新子句的生成:
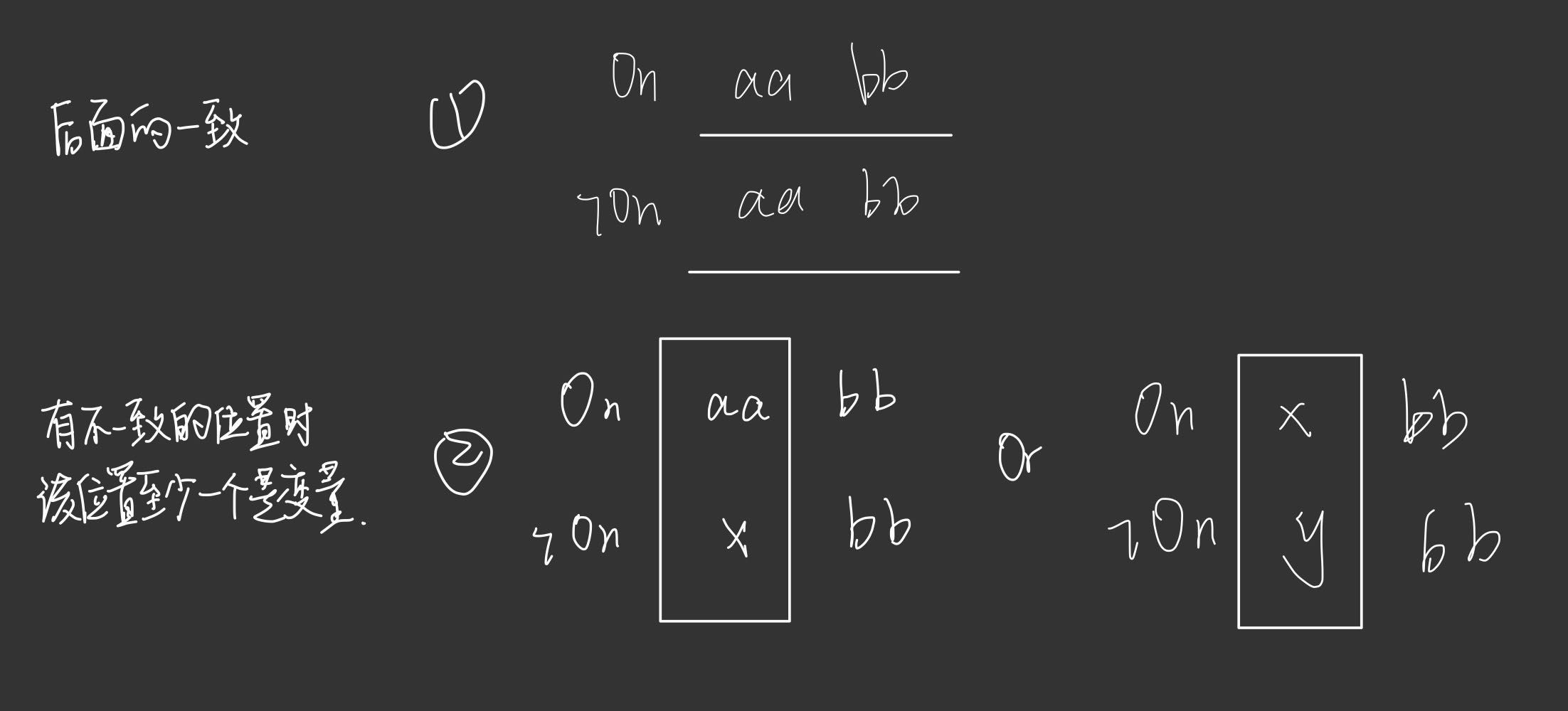
- 情况一:谓词相反,后面部分全部相同
- 情况二:存在元素不一致的位置上,至少有一个是变量
1 | # 判断能否生成新子句: 对已经变量替换后的处理 |
然后进行新子句的生成:对于两个子句ki,kj位置上的事实,在合一后已经可以消去,所以将其他位置的事实加入到temp_str中,最后再对temp_str去掉重复的元素得到new_str。
1 | if judge_resolution(replaced_si[ki], replaced_sj[kj]): |
去除无用子句
实际上就是回溯遍历:找某个新子句是由哪两个子句生成的过程。
这里使用队列进行广度优先遍历,先将parents的尾节点加入队列,然后将路径上的新子句加入 t_ans_idx 中(这里记录的是原子句集s中的下标对应关系,而不是子句)。
然后再得到结果(子句生成过程集合):先加入初始子句集中的元素下标,再加入 t_ans_idx 中不是初始子句集中的元素 下标,便得到新的 reindex 和原子句集s的下标 id 的对应关系。
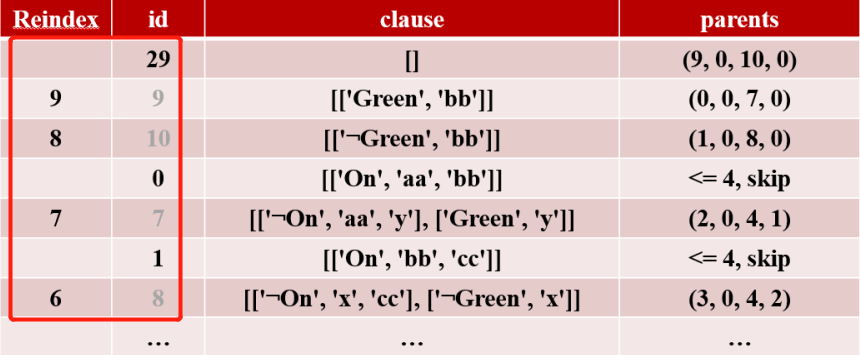
1 | # 去除无用子句 |
对结果进行格式化输出
目标格式:
1 | R[1a,2c]{X=a} (Q(g(a)),R(a),Q(z)) |
对输出结果进行观察可以得到以下几个要点:
- 输出的结构是
R[父子句1(事实的位置),父子句2(事实的位置)]{变量的替换} 生成的新子句 - 若父子句只有一个元素则不用输出事实的位置
- 若不用变量替换也能生成新子句,则不用输出变量的替换
- 对尾部语句单独处理即可
1 | # 输出 |
创新点&优化
优化的一个直观表示为缩减 子句集s 的长度,虽然它不表示生成过程经历的总步数,但它一定程度上可以反映进入小循环的次数,这是耗时的一大部分之一。
- 优化一:使用找变量的逻辑
is_value和find_value,对两个子句进行相同的寻找变量并替换处理,两个子句即使位置交换也不影响结果,提高鲁棒性 - 优化二:在循环中不固定当前循环的长度。这样子可以更多地组合旧子句和新子句,而不用等待一轮最外层遍历结束之后才能访问新子句。(当然固定长度时也有优化办法:只遍历旧子句和新子句,只是优化效果不明显)
- 优化三:判断在最外层循环中判断 i<j 才进入单步归结。这是因为在外层循环中每两个子句只用进行一次归结,且自己和自己不用归结
- 优化四:如果该新子句已经在子句集S中出现过,则撤销本次单步归结(避免重复的子句生成),从而缩短子句集s的长度
注意:优化四 有个问题是在判断新子句是否存在于子句集s中还要进行一次搜索,而这次搜索会比较影响时间执行的效率,在程序执行时间成本不大的情况(比如测例2)下优化效果不明显。
注:以上的优化均基于对每两个子句之间的暴力搜索,使用一部分剪枝优化。若使用别的搜索策略比如bfs或者dijikstra会得到更优的结果。
实验结果及分析
测例一
优化前:
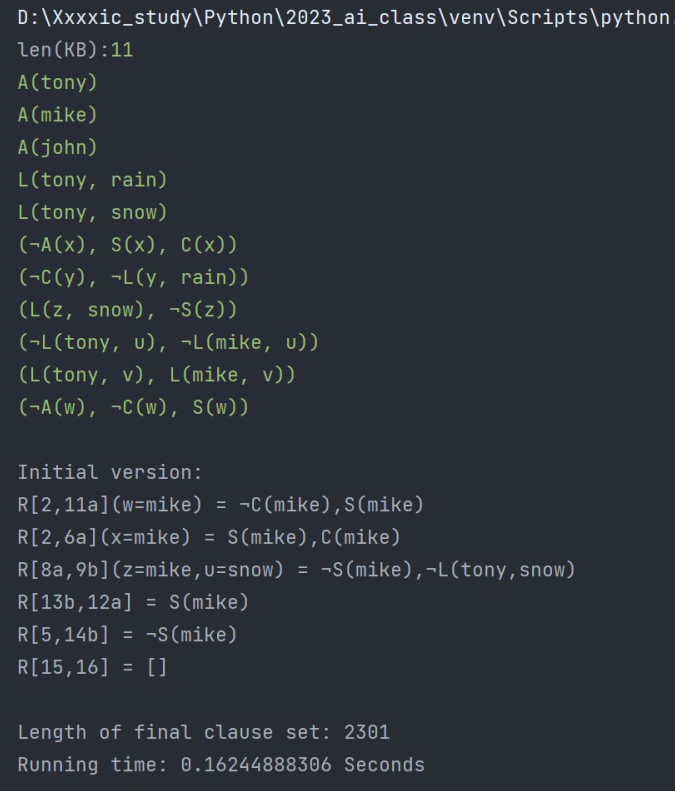
优化后(采用优化四):
优化后(不采用优化四):
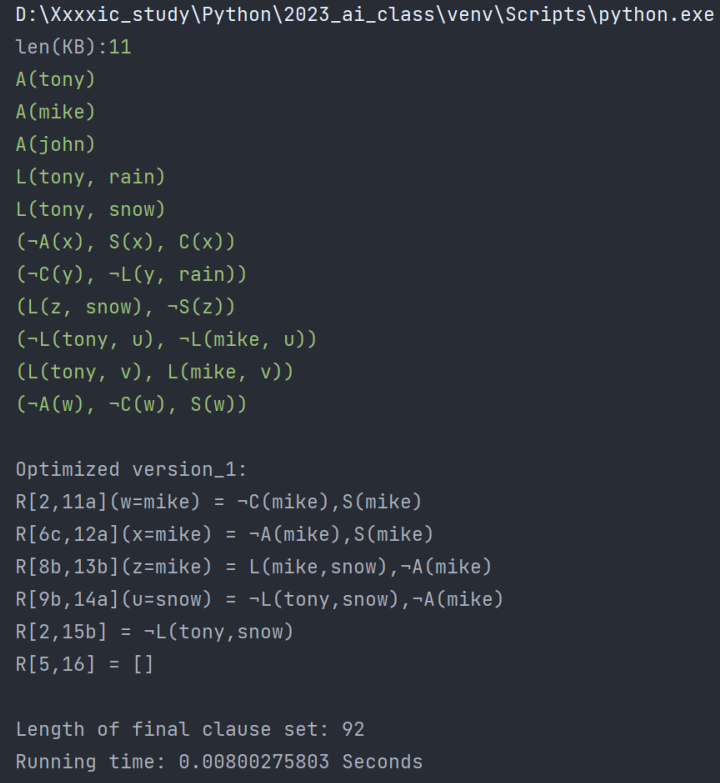
| 程序运行时间/s | 子句集长度 | |
|---|---|---|
| 优化前 | 0.16244888306 | 2301 |
| 优化后(采用优化四) | 0.00800275803 | 92 |
| 优化后(不采用优化四) | 0.00901198387 | 144 |
测例二
优化前:
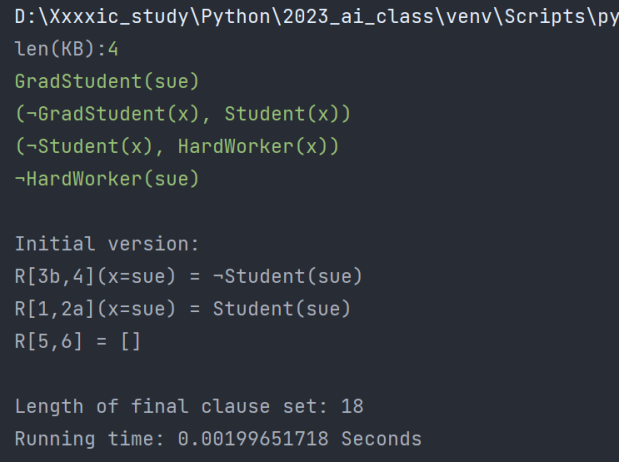
优化后(采用优化四):
优化后(不采用优化四):
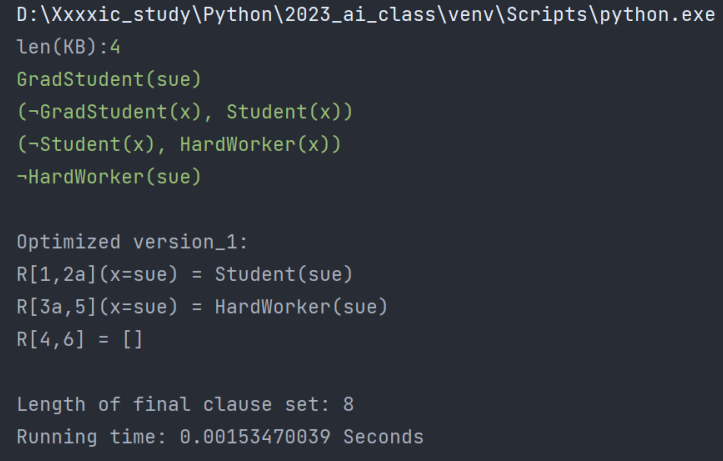
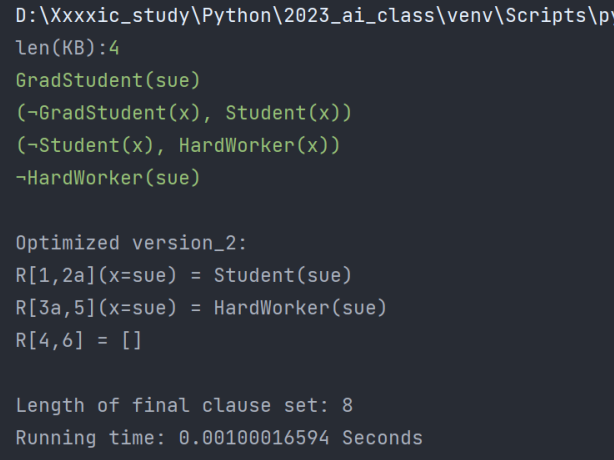
| 程序运行时间/s | 子句集长度 | |
|---|---|---|
| 优化前 | 0.00199651718 | 18 |
| 优化后(采用优化四) | 0.00153470039 | 8 |
| 优化后(不采用优化四) | 0.00100016594 | 8 |
测例三
优化前: 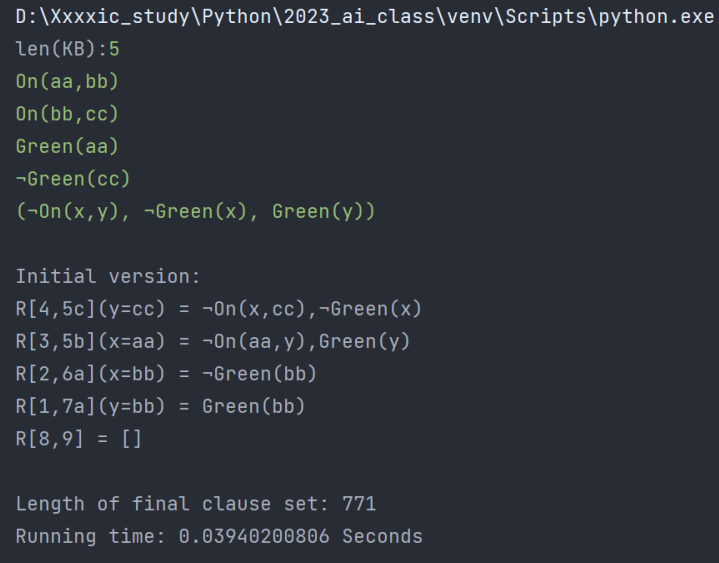
优化后(采用优化四):
优化后(不采用优化四):
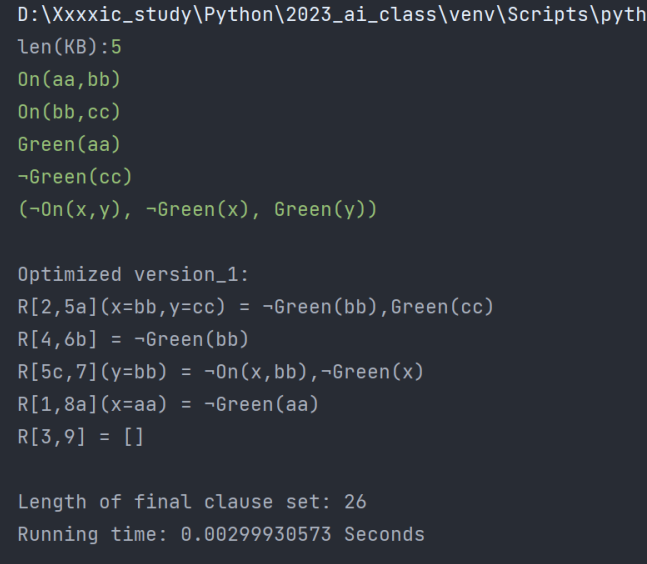
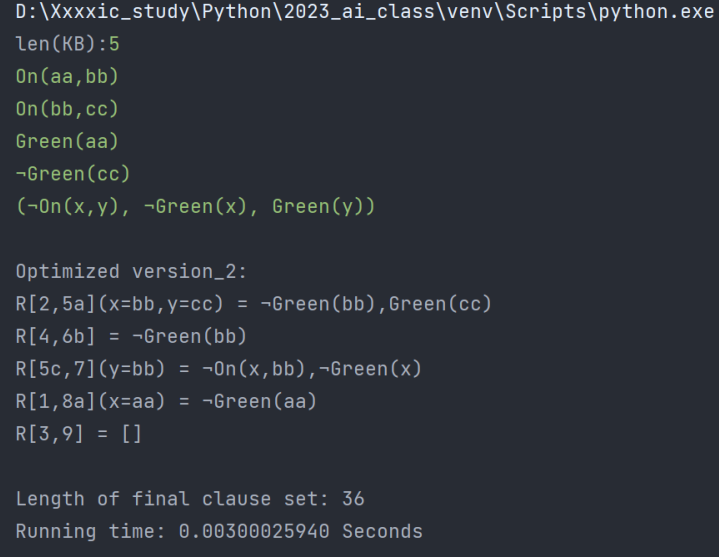
| 程序运行时间/s | 子句集长度 | |
|---|---|---|
| 优化前 | 0.03940200806 | 771 |
| 优化后(采用优化四) | 0.00299930573 | 26 |
| 优化后(不采用优化四) | 0.00300025940 |
36 |
值得注意的是:空子句的生成路径不唯一。
采取优化之后输出结果和优化前不一致,但都是正确的生成路径,这是优化二中使用了可变长度的遍历导致遍历顺序的改变造成的。
综上,在采取优化之后缩短子句集的长度,缩短程序执行时间。
- 在输入量比较小的样例中可以不使用优化四来减少搜索的时间成本
- 在输入量大的样例中建议采用优化四来缩减子句集长度
LAB3 启发式搜索
要求
使用 A* 与 IDA* 算法解决 15-Puzzle 问题,启发式函数可以自己选取,最好多尝试几种不同的启发式函数,完成 ppt 中的测例。
- 需要包含对两个算法的原理解释
- 需要包含性能和结果的对比和分析
- 如果使用了多种启发式函数,最好进行对比和分析
- 需要分情况分析估价值和真实值的差距会造成算法性能差距的原因
参考资料
课程文件 Lab3_启发式搜索
实验内容
算法原理
十五数码问题:是在 4×4 的棋盘上,摆有 15 个刻有 1~15 数码的将牌。棋盘中有一个空格,允许紧邻空格的某一将牌可以移到空格中,这样通过平移将牌可以将某一将牌布局变换为另一布局。针对给定的一种初始布局,问如何移动将牌,实现从初始状态到目标状态的转变
A*算法
A*算法是一种启发式图搜索算法,可以指导搜索向最有希望的方向前进。对于一般的启发式图搜索,总是选择估价函数 f 值最小的节点作为扩展节点。
评估函数 $f(n)=h(n)+g(n)$
- 从起始节点到节点 n 的实际代价 g(n)
- 从节点 n 到达目标节点的最优路径的估价代价 h(n),且 h(n)≤h*(n) , h*(n) 为 n 节点到目的结点的最优路径的实际代价。
算法步骤:从起始节点开始,不断查询周围可到达节点的状态并计算它们的 f(x)、h(x)与 g(x)的值,选取估价函数 f(x)最小的节点进行下一步扩展,并同时更新已经被访问过的节点的 g(x),直到找到目标节点。
对于十五数码问题而言,g(n)为当前空位移动的步数,启发函数则有多种选择,设 open_set 为叶子节点,close_set 为非叶子节点。每次遍历从叶子节点 open_set 中取出 f 值最小的那一个,然后将其加入 close_set 中,对其进行叶子的生成,判断它是否为结果,并且将其叶子加入 open_set 中。如果通过它能使得 f 更小,那么就更新。
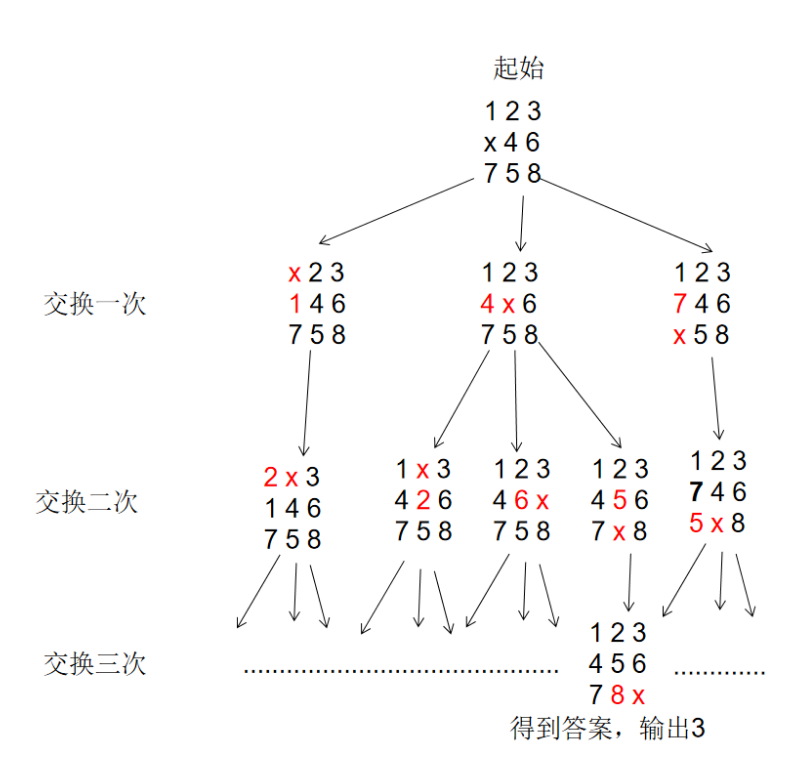
两种返回方式:直到队列为空、找到目标返回(剪枝)
伪代码如下:
1 | 初始化open_set和close_set; |
IDA*算法
IDA* 是迭代加深 Astar,每一次迭代都选择当前最小估价函数值进行深度优先搜索,这很好的解决了空间问题,当当前状态的估价函数值大于阈值时,则进行回溯并将阈值更新为刚刚的估价函数值,若没有找到则扩大阈值,增大圆圈范围继续寻找,不断循环迭代直到找到目标状态。因为它不需要去维护表,因此它的空间复杂度远远小于 A* 。在搜索图为稀疏有向图的时候,它的性能会比 A* 更好。
算法步骤:迭代的每一步,IDA*都进行深度优先搜索,在某一步所有可访问节点对应的最小可估价函数值大于某个给定的阈值的时候,将会剪枝。对于给定的阈值 bound,定义递归过程:
- 从开始节点计算所有邻居节点的估价函数,选取估价函数最小的节点作为下一个访问节点
- 对于某个节点,如果估价函数大于阈值,则返回当前节点的估值函数值
- 对于某个节点,如果是目标节点,则返回状态 ”到达”
伪代码如下:
1 | IDA_search(bound) |
关键代码展示
对于某个给定的初始状态,可以先用逆序对来判断是否有解:
1
2
3
4
5
6
7
8
9
10# 逆序对个数为偶数个:有解
def isSolvable(s):
cnt = 0
for si in range(16):
if s[si] == '0':
continue
for sj in range(16):
if int(s[si], 16) > int(s[sj], 16):
cnt += 1
return cnt % 2 == 0
A*
1 | def astar(start): |
IDA*
1 | def IDAsearch(path, cur_dep, Hx, bound): |
创新点&优化
实现方式的选择
对于十五数码问题,那个空位实际上是基于二维的图进行移动,所以第一个想法就是对一个二维的数据的处理,采取二维列表或者是 numpy 的形式。
但是考虑到其二维形状是 4x4 的固定表格且只有一个空位,所以也可以将它抽象成一维的数据进行处理,比如将 16 个数排成一列然后分别用 1-15 表示数码位,0 表示空位。更进一步的,将数据变为十六进制数存入一个字符串中进行处理。
可以发现一维的实现方式比二维的速度提高了不少
启发式函数的选取
在这里使用了三种不同的启发式函数:曼哈顿函数,切比雪夫函数以及错位码数函数,对其分别进行测试
曼哈顿
1
2
3
4
5
6
7
8
9
10
11
12def manh(u):
cnt = 0
for hi in range(16):
if u[hi] == '0':
continue
a = hi // 4
b = hi % 4
x = (int(u[hi], 16) - 1) // 4
y = (int(u[hi], 16) - 1) % 4
cnt += abs(a - x) + abs(b - y)
# cnt += ((a - x) ** 2 + (b - y) ** 2) ** 0.5
return cnt切比雪夫
1
2
3
4
5
6
7
8
9
10
11def chebyshev(u):
cnt = 0
for hi in range(16):
if u[hi] == end[hi]:
continue
a = hi // 4
b = hi % 4
x = (int(u[hi], 16) - 1) // 4
y = (int(u[hi], 16) - 1) % 4
cnt += max(abs(a - x), abs(b - y))
return cnt错位码数
1
2
3
4
5
6
7
8
9
10def misplace(u):
# 错位码数
cnt = 0
for hi in range(16):
if u[hi] == '0' or u[hi] == end[hi]:
# 0号状态位不计入
continue
else:
cnt += 1
return cnt
| Time/s | 测例 1 | 测例 2 | 测例 3 |
|---|---|---|---|
| 曼哈顿 | 0.001000 | 0.000426 |
7.148612 |
| 切比雪夫 | 0.024006 | 0.001000 | TimeOut |
| 错位码数 | 528.1 | 382.2 | 214.1 |
从测试结果上看,曼哈顿函数能够在保证最优解的情况下对算法执行效率有很大的影响,运行速度最快。对程序调试发现,错位码启发函数提供的最高的启发函数值也仅为 9,在搜索中超过了一定层次后, h(x)在 f(x)中的占比越来越小,程序退化成了盲目搜索。综上,三个启发式函数中,曼哈顿函数能够在保证最优解的情况下使程序更快的搜索,在后续实验中也将继续使用曼哈顿函数作为启发函数。
open_set
在算法中,我们需要在 openset 中选出评估函数 f 值最小的一个,作为拓展的节点去进行拓展。而这个过程其实和算法的执行时间也有不小的关系。
可以用列表放置节点,每次放入都进行一下排序,这无疑是低效的。在 python 中有优先队列的模块,这里我们将 openset 设置为优先队列,来提高每次取出最小 f 值节点的速度。
值得注意的是,python 中有 PriorityQueue 和 heapq ,其中 PriorityQueue 是线程安全的,它需要实现锁以确保线程安全,因此比 heapq 慢。因此考虑到十五数码的实现情景,将使用 heapq 来进行 openset 的优化。
| Time/s | 测例 1 | 测例 2 | 测例 3 |
|---|---|---|---|
| 优化前 | 0.795587 | 0.948143 |
9.72 |
| 优化后 | 0.001976 | 0.001000 | 8.16 |
close_set
closeset 是用于存放当前状态下已经确定最优路径的节点,在每次节点拓展时都会查询该拓展节点是否已经在 closeset 内,来决定是否剪枝或者进行节点拓展,而这个查询搜索的过程与算法执行时间有关联。
- 第一个想法是使用列表 list 的搜索,但是经过查询资料:list 的搜索并没有 hash,也就是说其搜索并不高效。
- 所以可以将 list 优化成字典 dict,即上面代码展示的 dis(用于存放一个节点以及其当前走过的步数),这样子可以使用
dis.setdefault(temp)来查找 temp 是否存在于 dis 中,不仅提高了效率,还简化了实现的逻辑细节。 - 实际考虑到空间和时间的效率,set 在频繁的查询需求情景下是比字典 dict 更优的,所以还可以将 close_set 设置为 set 来提高查询的效率。(不过经过我测试,set 效率和 dict 差不了太多,为了简化逻辑最终还是采用了 dict)
多进程优化
在跑困难样例时我去观察了一下电脑的性能使用情况,发现在内存接近满载运行的情况下,CPU 占用居然只在 20% 上下浮动,观察到多核 CPU 只有三四个在运行,所以考虑对程序作并行化改造,从而达到计算复杂型程序的多进程优化。

对十五数码程序进行观察可以发现程序实际上就是不断的进行大循环,直到优先队列为空或者达到目标状态退出,这个大循环有着紧密的层层依赖关系,所以对外层大循环进行并行计算的分割处理困难。再对内层的小循环观察,发现可以对这 4 次循环上下左右方向进行并行计算的尝试。
这里调用了 python 的 multiprocessing 库,进入循环前先开进程池,然后用 apply_async 调用封装好的 near_node_search(),这里有个细节就是考虑到消息传递的问题,传参时不能涉及除 multiprocessing 库外的队列,否则子进程不会进入执行。在循环结束时 pool.close() 等待全部子进程执行完毕再 pool.join() 进行下一轮循环。
可惜的是,结果并没有提高执行的速度,反而在程序中进行打印的插入可以发现在进程池的创建关闭时会出现不明显的停顿,多次循环的反复开关进程池反而降低了程序的执行效率。
本项优化旨在提高程序运行速度而不是提高 CPU 占用率,实际上还可以使用效率更高的 python 解释器、关键代码用 C/C++ 重写等方法,在其他方法尝试过的情况再考虑多进程优化,因为很多时候盲目引入多进程的同时会带来了许多的问题,需要对计算进行仔细的分割处理,在这里的内层循环中使用反而因为频繁反复地开关进程池消耗了大量的时间,没有达到优化的效果。
双向 A*
在学习 BFS 广度优先搜索时了解到双向 BFS,可以非常大的提高单个 bfs 的搜索效率

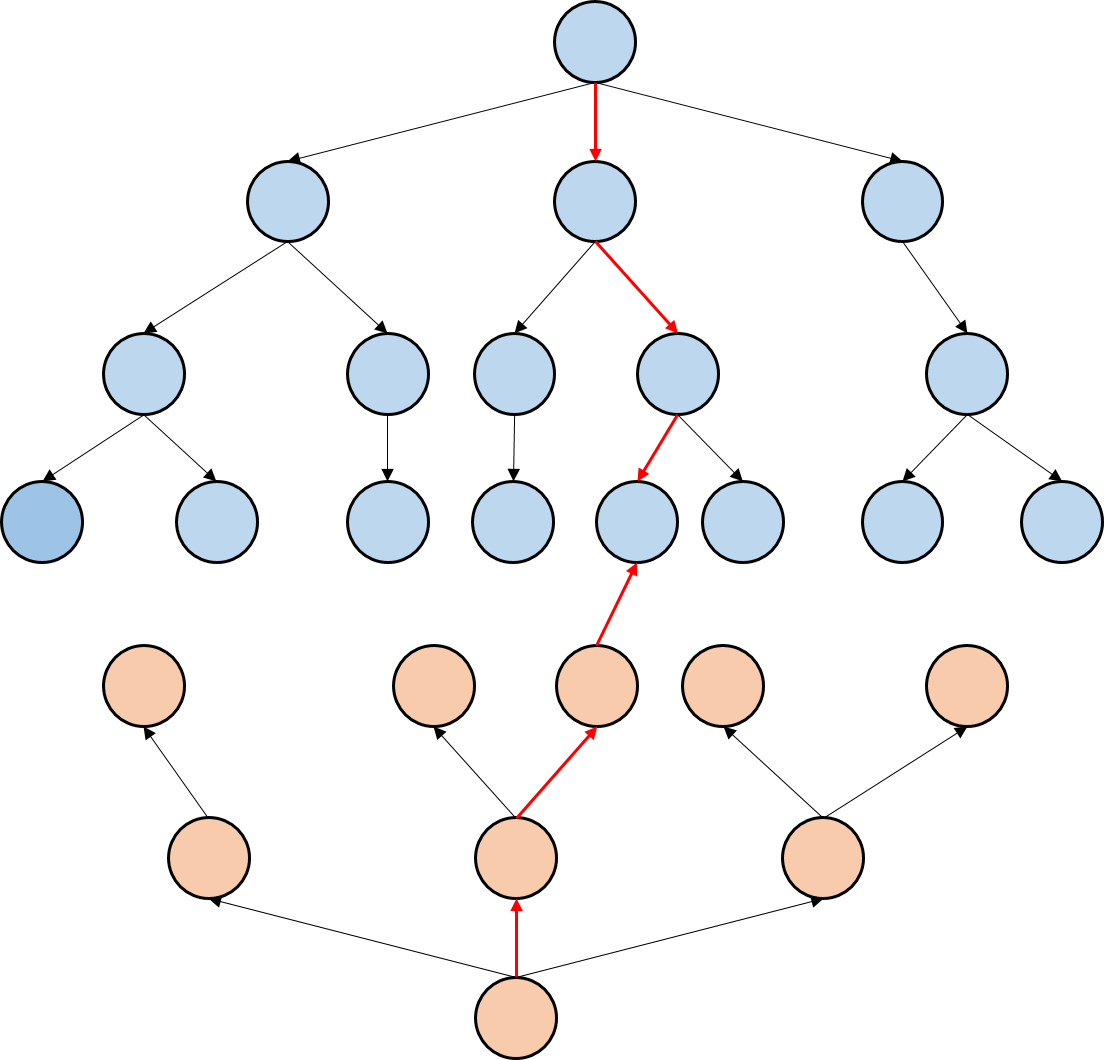
同样的思路可以考虑实现双向 A*,也是同样通过设置两个队列,一个队列保存从起点开始搜索的状态,另一个队列用来保存从终点开始搜索的状态,如果某一个状态下出现相交的情况,那么就出现了一条路径
于是对上面的思路进行实现即得到如下代码,对结果进行输出可以观察到前半部分和后半部分的两段路径,以及路径的总长度,并且可以发现速度提高了很多

但在困难样例中通过对步数的观察,发现得到的结果并不是最优的,这是因为逆向 A*的启发式函数的选择问题,尝试过逆曼哈顿,错位码数等启发函数均保证解的最优性。但观察困难样例输出的步数,仅比最优解多了几步,但其使用时间却提高了数十倍不止。
实验结果及分析
采用了以上的优化之后,对测例进行运行,其中的一些实验结果展示:
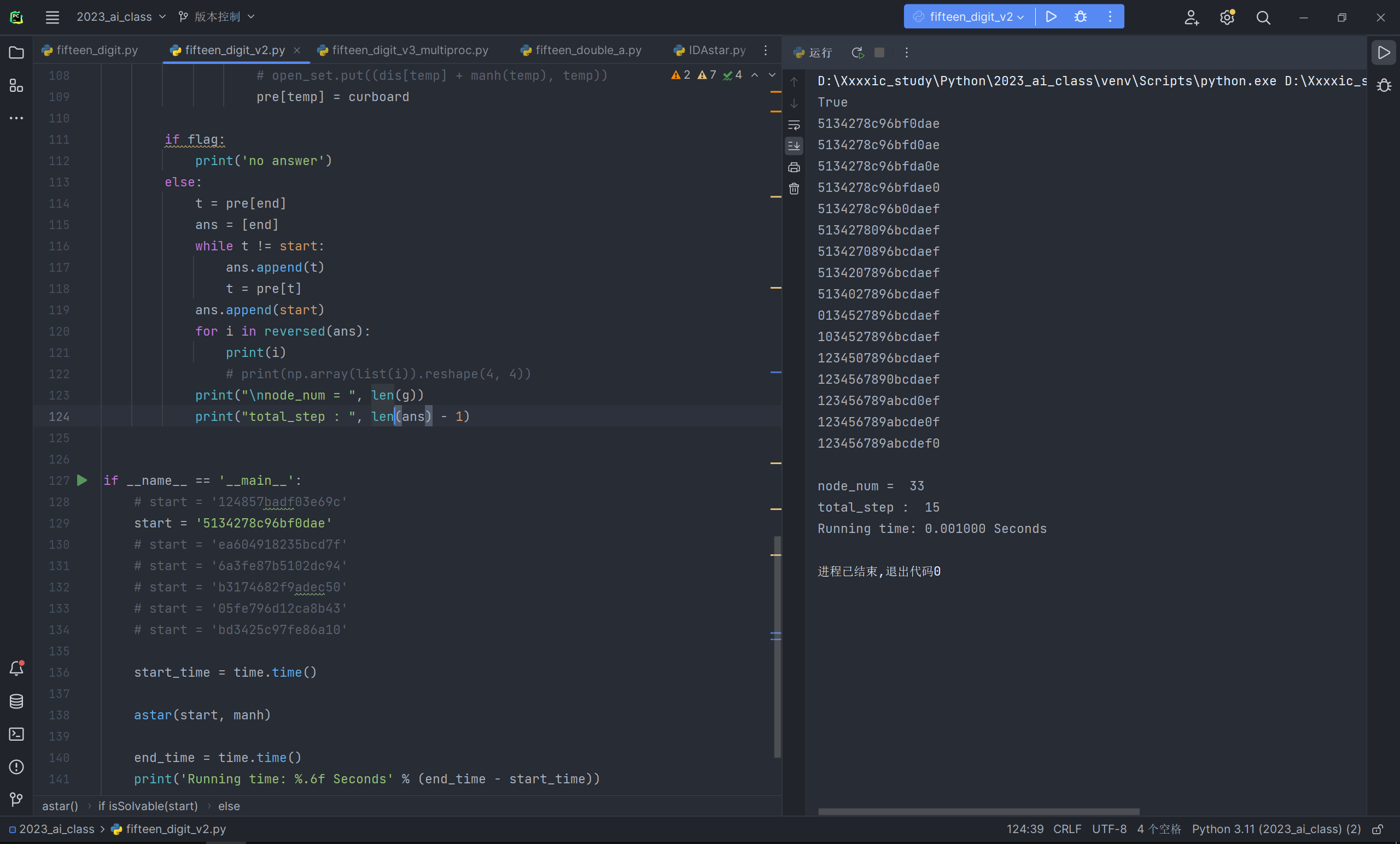
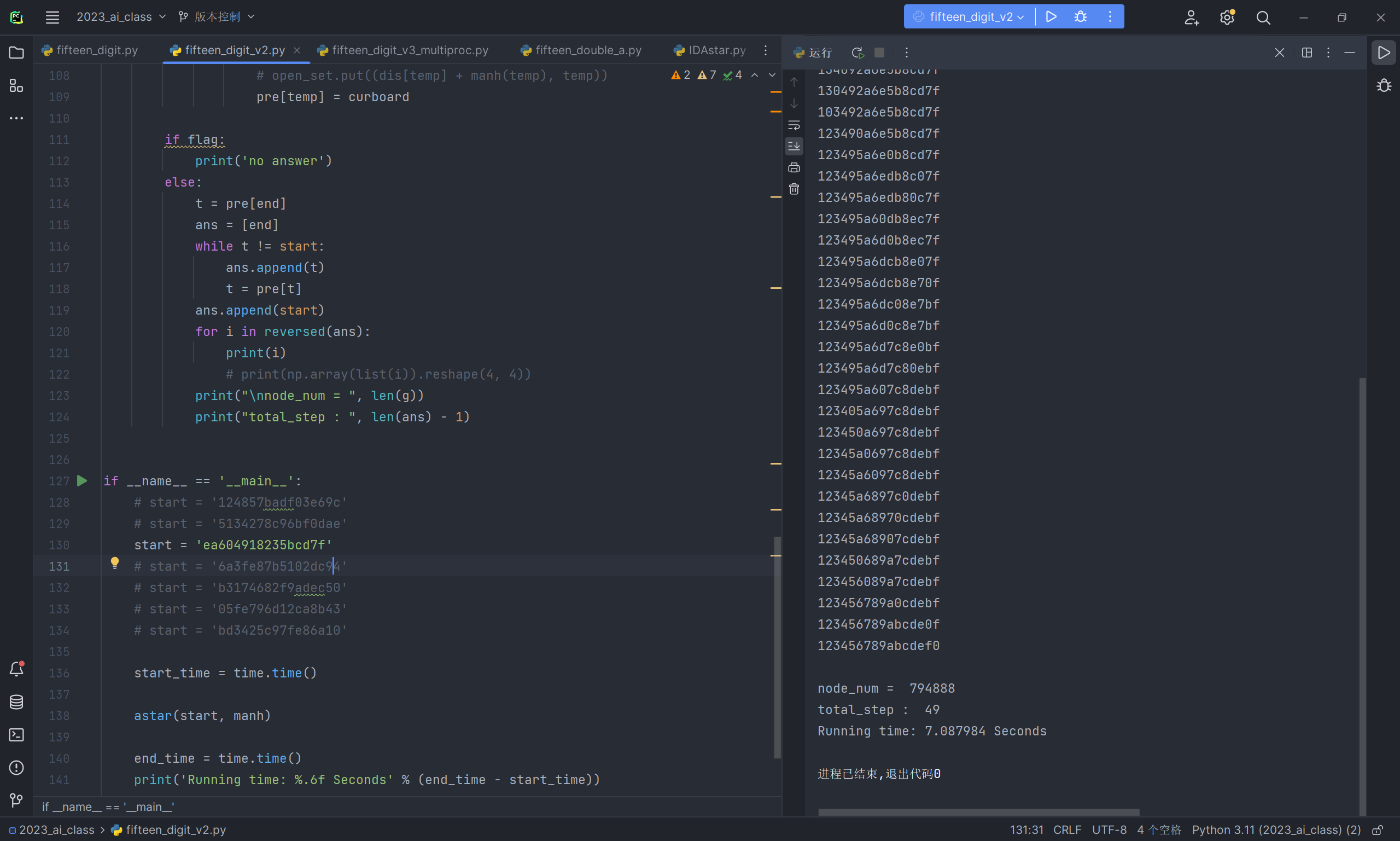
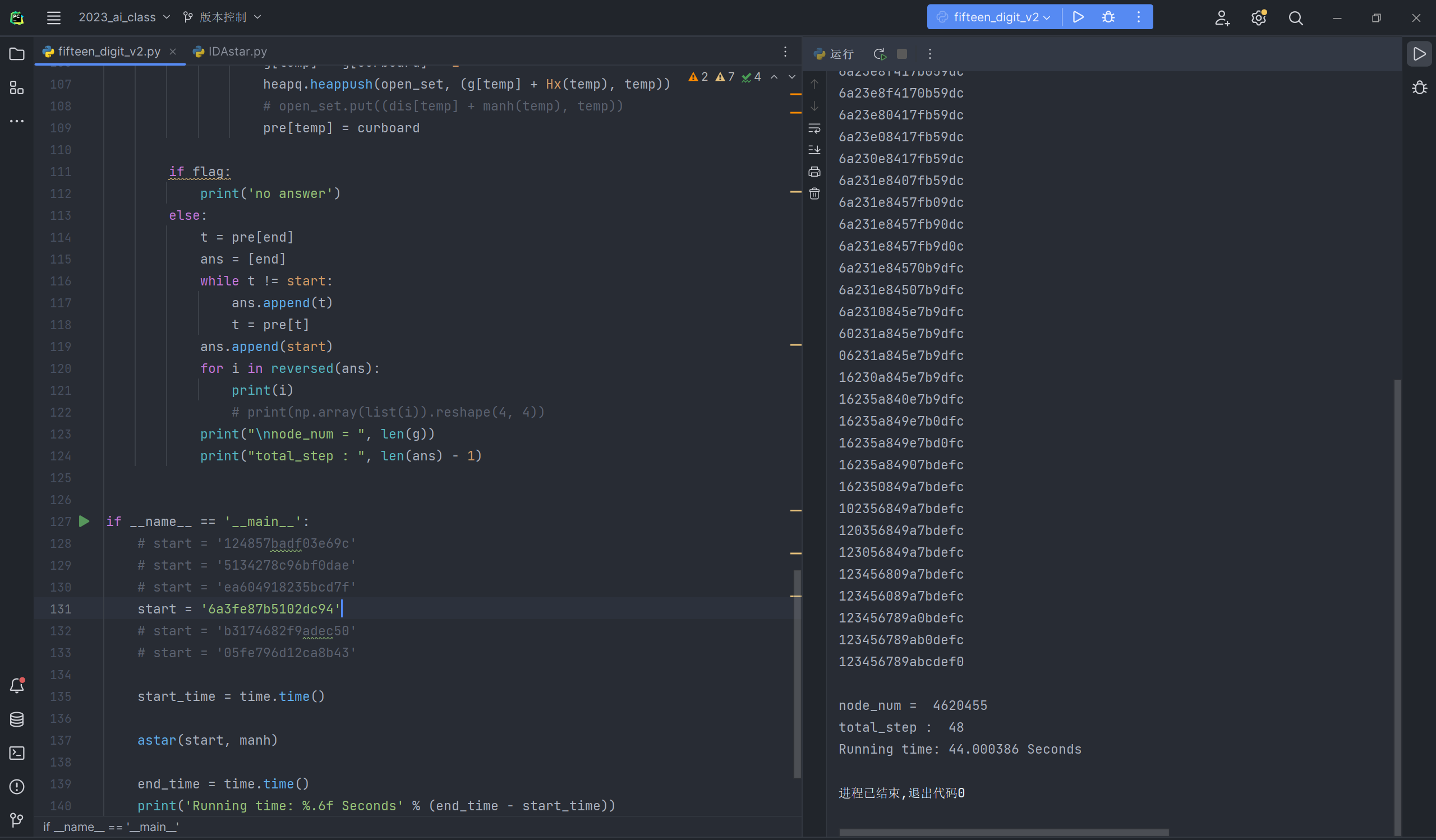
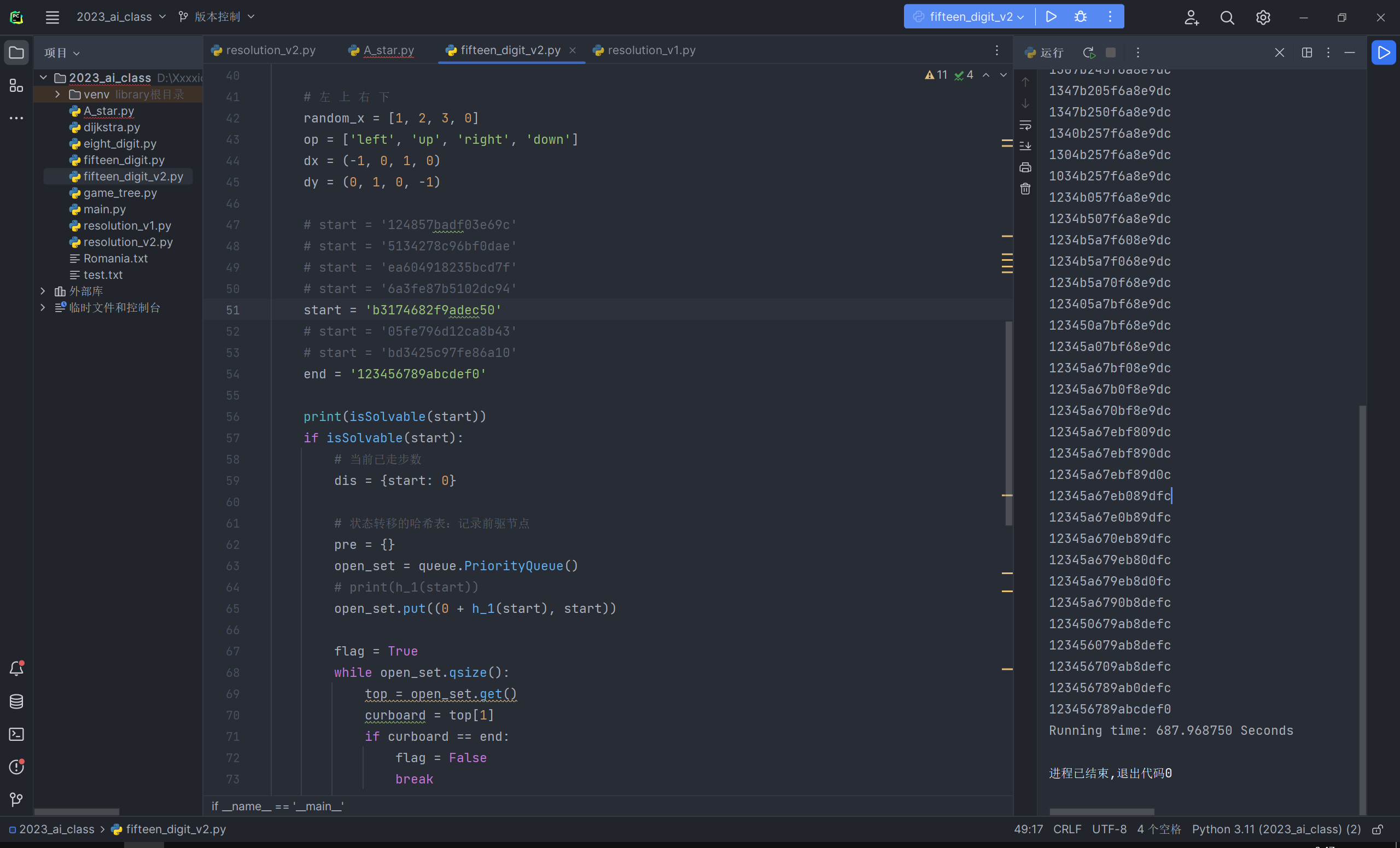
具体数据在以下表格:
| 测例 1 | 测例 2 | 测例 3 | 测例 4 | 测例 5 | 测例 6 | |
|---|---|---|---|---|---|---|
| A* | 0.015625 | 0.948123 | 19.09362 | 67.5433 | TimeOut | TimeOut |
| A*优化后 | 0.002000 | 0.001000 | 7.087984 | 44.0003 | 687.97 | 568.89 |
| IDA*优化后 | 0.003885 | 0.002006 | 21.63232 | 82.7481 | 4031 | 3987 |
搜索速度还是准确度?
对 A*中的启发函数 $f(n)=g(n)+h(n)$,考虑以下情况下:
- h(n)趋近于 0,那么只有 g(n)起作用,此时 A*也就是 dijikstra 算法,它保证一定可以找到一条最优路径
- h(n)总是小于等于从结点 n 走到目标结点的步数,A*算法一定可以找到最优路径。h(n)越小,A*扩展的结点越多,导致 A*算法越慢
- h(n)==从结点 n 走到目标结点的步数,A*算法扩展的所有结点都在最优路径上,此时算法速度非常快
- h(n)有时大于从结点 n 走到目标结点的步数,那么将无法确保能够找到最优路径,但会运行得更快
- h(n)非常接近于 g(n),那么只有 h(n)将起作用,A*算法实际上变成贪心搜索
实际上在游戏中,A*的这种特性是非常有用的。举个例子,在游戏的地图寻路中,玩家宁愿更快得找出较优路径而不是慢悠悠等着最优路径。而且在速度和准确度上的选择并不一定是一成不变的,这个可以动态地权衡,这决定于 CPU 的速度、找出路径的时间对游戏的影响、地图上的结点重要程度、游戏的难度级别,或者其他的一些因素。
以上可见在 A*算法中进行启发函数的设计是十分灵活的,取决于具体业务的需求,而在十五数码问题中我们当然愿意用更久的时间去得到一条最优路径,但假如要我们需要在有限的时间内得到较优路径,我们便可以对启发函数进行改动,比如对权值进行修改或者进行幂乘:
这里对曼哈顿距离幂乘 1.6,比最优步数多了 6 步,时间却从 44s 降低到 0.05s

| Time/s | 测例 3 | 测例 4 |
|---|---|---|
| 优化前 | 7.087984 |
44.0003 |
| 优化后 | 0.405597 | 0.05001 |
更一般的,对某个业务场景进行数据的提取,比如游戏某张地图的寻路,整合成数据集放入深度学习的模型,将启发函数的权值或者幂作为超参数进行训练,去提高这个业务场景下速度和准确度。
LAB4 Alpha-beta 剪枝
要求
编写一个中国象棋博弈程序,要求用 alpha-beta 剪枝算法,可以实现人机对弈。
棋局评估方法可以参考已有文献,要求具有下棋界面,界面编程也可以参考网上程序,但正式实验报告要引用参考过的文献和程序。
任务:实现一个基础的象棋界面和基本下棋的功能之后,考虑植入 ai 下棋功能。
在轮到一方 ai 下棋时传入当前棋盘信息,ai 根据棋力表判断棋力,然后遍历己方棋子生成新棋盘得到新棋力,在这个过程利用 alphabeta 剪枝,最后返回结果最好的一种下法。
- 课程文件 Lab4_博弈树搜索
- MTD(f) - Wikipedia
- 象棋巫师 - 象棋百科全书 (xqbase.com)
- 谢艳茹. 中国象棋计算机博弈数据结构与评估函数的研究和实现.西安理工大学.2008 年
- 杜向然. 基于 PSO 的中国象棋评估函数的研究[D].河北大学,2010.
关于博弈树的历史启发_历史启发算法_trancybao的博客-CSDN博客
并行博弈树搜索算法-第4篇 更上一层楼:Alpha-Beta算法的改进 - myjava2 - 博客园 (cnblogs.com)
手把手教你实现最强四子棋AI - 知乎 (zhihu.com)
中国象棋python实现(拥有完整源代码) Alpha-beta剪枝+GUI+历史启发式+有普通人棋力_象棋人机对战程序_Veritaswhs的博客-CSDN博客
实验内容
算法原理
MiniMax 算法
MiniMax 算法是一种找出失败的最大可能性中的最小值的算法,是博弈问题中常用的搜索策略。
在局面确定的双人对弈里,常进行对抗搜索,构建一棵每个节点都为一个确定状态的搜索树,每一层轮流表示 MAX 方和 MIN 方的决策(在限制深度内)。博弈树上每个叶子节点都会被赋予一个估值,估值越大代表我方赢面越大。 我方追求更大的赢面,而对方会设法降低我方的赢面,体现在搜索树上就是,MAX 层节点(我方节点)总是会选择赢面最大的子节点状态,而 MIN 层(对方节点)总是会选择我方赢面最小的的子节点状态。
过程:会从上到下遍历搜索树,回溯时利用子树信息更新答案,最后得到根节点的值,意义就是我方在双方都采取最优策略下能获得的最大分数。


alpha-beta 剪枝
朴素的 Minimax 算法常常需要构建一棵庞大的搜索树,时间和空间复杂度都将不能承受。在 MIN、MAX 不断的倒推过程中若满足某些条件,则可以去掉一些不必要的搜索分支以提高算法效率,而 $\alpha-\beta$ 剪枝就是利用搜索树每个节点取值的上下界来对 Minimax 进行剪枝优化的一种方法。
若已知某节点的部分子节点的分数,虽然不能算出该节点的分数,但可以算出该节点的分数的取值范围。记 $\mathit{v}$ 为节点的分数,且 $\alpha \leq v \leq \beta$,即 $\alpha$ 为最大下界,**$\beta$** 为最小上界。当 $\alpha \geq \beta$ 时,该节点剩余的分支就不必继续搜索了(也就是可以进行剪枝了)。注意,当 $\alpha = \beta$ 时,也可以剪枝,这是因为不会有更好的结果了,但可能有更差的结果。
其详细规则描述如下:
- alpha 剪枝。若任一 MIN 层结点有 alpha(前驱层) >= beta(后继层),则可终止该 MIN 层中这个 MIN 结点以下的搜索过程。这个 MIN 结点最终的倒推值就确定为这个 beta 值。
- beta 剪枝。若任意 MAX 层结点有 alpha(后继层) >= beta(前驱层),则可以终止该 MAX 层中这个 MAX 结点以下的搜索过程。这个 MAX 结点最终倒推值就确定为这个 alpha 值。
伪代码

更具体点:
1 | # 深搜 |
关键代码展示
对于本次实验的任务来说,需要搭建一个中国象棋的 ui 并设计象棋的行走规则,首先实现人人对下的功能,在这个基础上再补充象棋 ai 的功能,补充象棋的评估函数,再利用博弈树搜索和 alphabeta 剪枝完善象棋 ai 功能。
对于象棋 ui 的实现,这里参照资料选择 pygame 库的实现方法:
1 | ├── images // 存放项目使用到的资源文件 |
本次实验的重点实现函数 alphabeta() 剪枝和返回下一步的坐标 get_next_step(),将上述的伪代码实现,代码如下:
1 | def get_next_step(self, chessboard: ChessBoard): |
创新点&优化
实现方式优化
棋盘表示的实现
在本次实验中棋盘是通过二维的 list 再封装成类来使用,考虑到上次实验中十五数码问题棋盘的表示,可以使用一维的形式来存储棋盘,不仅可以提高存储效率还可以提高运算速度。通过查阅参考资料可以了解到性能更加好的位棋盘技术。
但基于重构项目的难度的考虑,本次实验实现的重点还是在 alphabeta 剪枝上面。
alphabeta 剪枝的实现
通过观察,可以发现 min 层与 max 层的代码非常相似,可以优化成如下形式
以下是伪代码,具体实现放置于 ChessAI.py 的
AlphaBeta_s() 内1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def AlphaBeta(depth, player, alpha, beta):
if depth >= max_depth:
return value
找到当前可以下的位置movable_positons
遍历:
for mov in movable_positons:
chessboard.mov
score = min(beta, AlphaBeta(depth + 1, nxt_player, -beta, -alpha))
chessboard.back
if score >= beta:
return score
if score > alpha:
alpha = score
return score
历史启发算法
代码存放在 ./history_heuristic.py 和 ./ChessAI.py 的 alpha_beta_h() 内
在 AlphaBeta 剪枝算法中,内部结点分支的择序对搜索的效率影响非常大
在博弈树中,同样的一个移动可能在不同的结点出现很多次,所以历史启发的基本思想是:维护每种不同移动的历史,记录移动对产生最佳博弈值方面有多成功,便于在搜索的时候,按照历史来对子树的搜索进行择序来提高剪枝效率。
即对节点(走法)排序,从而优先搜索好的走法,提升搜索的效率。 好的走法指可以引发剪枝的走法,或者是其兄弟节点中最好的走法。一经遇到这种走法,就给其历史得分一个相应的增量,使其具有更高的优先被搜索的权利
1 | class history_table: |
在上述代码中,HistoryTable 的每一项都对应着一种不同棋子移动方式。然后在 alphabeta 中拥有剪枝的分支中对好的走法进行记录,然后便于在下次搜索时可以提升搜索的效率。
在实现过程中有考虑过复用历史启发表的方式,但其复用不能仅仅是保存某一局的历史表然后在新一局中使用,因为这样子会导致之后的每一步都会在原来的基础上继续累加历史分数,而这不是原来想要的,所以就没有考虑进一步复用历史表。
搜索深度为 5 的情况下,搜索性能:
| 优化前 | 炮二平五 | 炮八进四 | 车九进八 | 车一平二 | 炮八平五 |
|---|---|---|---|---|---|
| 时间 / s | 61.74 | 27.78 | 20.94 | 9.51 | 9.43 |
| 评估节点数 | 2250343 | 1052517 | 797920 | 361434 | 377701 |
| 优化后 | 炮二平五 | 炮八进四 | 车九进八 | 车一平二 | 炮八平五 |
|---|---|---|---|---|---|
| 时间 / s | 54.19 | 22.78 | 18.10 | 7.10 | 7.12 |
| 评估节点数 | 1873688 | 754439 | 646215 | 238067 | 263942 |
置换表
代码存放在 ./TranspositionTable.py 和 ./ChessAI.py 的 alpha_beta_t() 内
置换表是一个大的直接访问表,存储了已经搜索过的结点的搜索结果,包括子树的博弈值、深度、alpha 和 beta 值。不管该子树是搜索完全得到了博弈值,还是只是完成部分搜索得到缩小的搜索窗口,由于重新搜索一个曾经搜索过的位置经常发生,所以使用置换表可以达到提高搜索效率的目的。
该操作是空间换时间,值得注意的是,在每次 alphabeta 搜索进去时都应该清空置换表,因为我的实现是不仅存储了精确的评估值,还存储某个深度的 alpha 和 beta 值,这样子可以提升单次搜索的效率,复用性稍微欠缺,提升了迁移性。
如果追求复用性的话,可以针对于某个棋局状态存储其评估值。甚至可以把置换表中的内容存储在文件中,每次搜索时进行更新。
1 | class TranspositionTable: |
经过验证,采用了置换表之后程序的性能大大提升,尤其是进入评估函数的次数极大地减少了,但可能由于程序实现原因在采用置换表后存在棋力变弱的情况,在修改实现为存储评估值的形式也许会改善。
搜索深度为 5 的情况下,搜索性能:
| 优化前 | 炮二平五 | 炮八进四 | 车九进八 | 车一平二 | 炮八平五 |
|---|---|---|---|---|---|
| 时间 / s | 61.74 | 27.78 | 20.94 | 9.51 | 9.43 |
| 评估节点数 | 2250343 | 1052517 | 797920 | 361434 | 377701 |
| 优化后 | 炮二平五 | 炮八进四 | 车九进八 | 车一平二 | 炮八平五 |
|---|---|---|---|---|---|
| 时间 / s | 5.998 | 6.889 | 0.167 | 1.354 | 2.362 |
| 评估节点数 | 23657 | 22513 | 479 | 18789 | 7421 |
MTD(f)算法
代码存放在 ./ChessAI.py 的 mtdf() 和 alpha_beta_m() 内
记忆增强测试驱动算法 Memory-enhanced Test Driver,是一种通过零窗口搜索和记忆化搜索实现的快速找到 Minimax 值的算法。
MTD-f 算法只使用零窗口进行搜索,来搜索在是否存在比下界值要大的值,如果是将新返回的值设为新的下界,否则设为新的上界,通过一系列的零窗口搜索,使原先初始的最优值边界从(-∞,+∞)逐渐收敛为一个确定的值,而这个值就是当前局面的最优值。
以下是 MTDF 的伪代码,其中我完成了函数的实现,但还未经过完善的测试,所以本次实验不予采用。
1 | def mtdf(self, root_chessboard, f, depth): |
评估函数
优化前的代码存放在 ./ChessAI.py 的 class Evaluate 内;优化后的代码存放在 ./ChessAI.py 的 class Evaluate_O 内
评估函数是启发式搜索的重要组成部分。
评估某一步棋的好坏时,不只是评估这步棋本身,而是评估在走完这步棋后形成的局面中双方的实力对比,这个实力对比和双方棋子数量及种类、棋子灵活度、棋子的威胁值、棋子的保护值等等有关。
在没有查阅更多的资料前我采用的评估函数仅仅是对棋力的评定,以至于在下棋时棋子是以单纯的子力驱动下棋,完全并没有章法可言。
经过查阅
子力:固定子力值是对棋子重要程度的评估
将 车 炮 马 相 士 兵 65536 989 642 439 210 226 55 空间:棋子在不同位置对局面的影响差别可能非常大,如兵卒在未过河前和过河后,因此不同棋子都有一个位置值数组来评价其在不同位置对局面的影响。
机动:棋子的灵活度指棋子的可移动范围,棋子的可移动范围大小对于棋子能否发挥能力很重要,如蹩马腿、蹩象腿等操作都会降低对方棋子的灵活度。
每一个棋子灵活度 = 棋子可走的格子数量 * 棋子的灵活度系数
将 车 炮 马 相 士 兵 0 7 13 7 1 1 1.5 单方的棋子总灵活度是将所有棋子的灵活度相加
相互关系
- 威胁值:棋子下一步可以吃对方棋子。被威胁值是指当前这个棋子处在多少个对方棋子的可移动位置上,也就是可能被吃,同样地,根据当前棋子的重要程度,它应该有一个权重修正,可以使用子力值进行修正
- 保护值:棋子下一步可以走到的位置刚好是己方棋子,就保护了这个棋子。被保护值是指当前棋子处在多少个己方棋子地可移动位置上,也就是说这个棋子被吃后有多少个己方棋子能为自己“报仇”,这个值同样可以根据自身的子力值进行修正(同样被保护或者威胁,棋子的重要程度会对这种威胁或保护有影响)
象棋相互关系的实现基于项目重构的难度就没有实现,所以在下到后期时可能会出现不考虑棋子之间牵扯关系而盲目吃子的情况,这对于象棋残局而言是致命的。
当在改进空间值的实现后,象棋的棋力得到了很大的提升,能够主动发动攻击和防守。特别是经过设置位置值,开局时可以进行许多指向的步骤,比如对方上炮我方上马,而不会在开局时直接用炮攻击对方的马进行自杀性吃子。
实验结果及分析

实验中设置搜索深度为 3,程序响应时间较好,几乎都在 0.5 秒内,棋子数越少响应速度越快。程序具有一定的棋力,能够主动发动攻击和防守,每次至少能够对战几十回合,愚蠢行为很少(例如白白送上棋子被吃),总体棋力接近正常人, 但对于较高水平的玩家仍十分吃力,这与评估函数的设计和搜索深度有关。具体演示结果在 压缩包/result 中有视频演示。
在程序的设计中可以意识到静态估值函数的重要性,他决定了棋子的走向决定了输赢。对于程序性能而言,静态评估函数的设计也会影响剪枝的效果,若静态函数的函数值过于集中,则有可能使得剪枝的概率变小,增加所需搜索节点的个数。
还有一个发现是,程序难以设计多个连续走步来威胁对方的将,即程序的攻击和防守策略比较简单。这也与评估函数的设计有关,更好的象棋程序甚至可以建立棋库,比如开局库和残局库,学习和调用优秀的走法。
我们的目的是利用好的估值函数和合适时间内尽可能大的搜索深度,提升棋局的赢面。但在评估函数给定的情况下,通过许多优化来提升程序的效率也十分重要,除了以上提到的几种优化,还有关键代码 c++ 重写,GPU 计算等方法,都是为了提高搜索深度而服务的。
我还尝试了两个 ai 对下的棋局,这个尝试比较有意思,还可以观察程序运行鲁棒性。可以发现在 ai 下棋下到残局时,ai 往往就会在某两步对自己有利的位置反复横跳,导致死局的情况出现,但实际上还是有翻盘的可能性,但需要走出传统意义上的坏棋,比如故意卖破绽等。不过这些都仅仅是建立在评估函数还不够完善的情况下,事实上目前的评估函数不仅有静态的还有动态的,利用神经网络进行训练后的评估函数具有更全面的评估能力,比如 *AlphaGo * 就是基于蒙特卡洛树搜索和神经网络训练的。、
还有值得一提的是这次实验的 debug 难度和以往实验对比难了许多,主要是没有找到在 pygame 内进入单步调试或者断点的方法,我尝试过别的思路比如 print 状态信息,但对于繁多且关联性较大的变量而言还是过于麻烦了。
举个例子,我偶然发现在即将下赢 ai 时会闪退(实际上很多情况下我下不过它),由于 pygame 开调试就进不去我就无法复现那一步,所以我想到了改变初始棋局的办法,最终找到了 由于 ai 无子可下导致的返回变量未初始化 的 bug。
